Publications
publications by categories in reversed chronological order. generated by jekyll-scholar.
2026
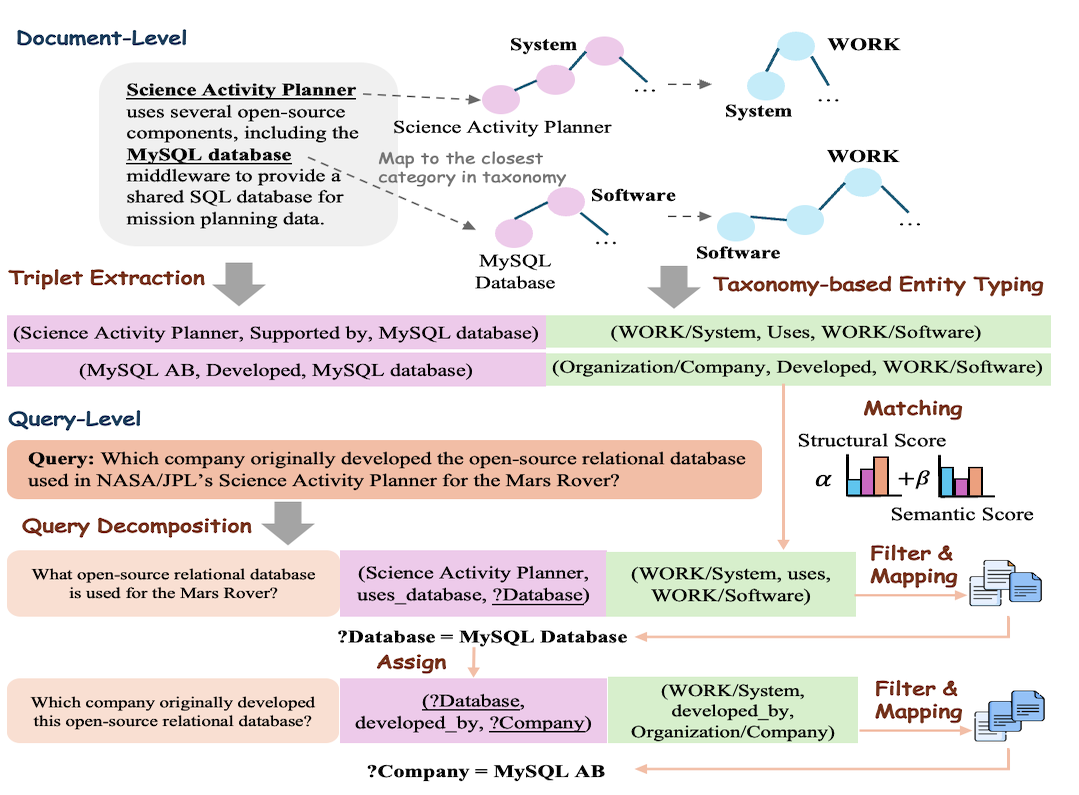
2025
- ExploratoryProgressive Structure Extraction: From Explicit to ImplicitEarly-stage exploratory work; not currently under active development.
- CollaborationEfficient Reasoning, Factual Certainty: A Dynamic Interaction between Generalist and Specialist Models for Medical ReasoningCollaborative project; I contributed to model training.